Cloud Costs
What are the costs to access the Data Lakes?
While cloud computing costs may vary, downloading data is free for end users. This can be achieved with or without an AWS account using the AWS CLI or manually via data-catalog viewers. Additionally, certain datasets are accessible free of charge via Highly Scalable Data Service (HSDS) and Jupiter Notebooks. For more complex operations, use AWS Athena for a small fee, often less than $1 USD. Combine with AWS SageMaker Studio Lab to run machine learning algorithms against the data at no cost to end users.
* Host account must grant users access to nodes through Cognito.
Manual Download and AWS CLI
Users with workflows requiring files in their local environment will benefit from the data-catalog viewer and AWS CLI (Amazon Web Service Command Line Interface). Download a single file or collection directly from the web browser. Alternatively, use scripted downloads with AWS CLI to batch the process and save time. To copy the relevant command, click the next to the "AWS CLI Access" line, directly under the resource. See AWS CLI turorial.
- User requires a specific dataset to process locally.
- By manually downloading datasets via data-catalog viewer, user can process data in ways they see fit.
- Total cost to end user: Free
- User requires various collections of datasets to process locally.
- User accesses data lake via AWS CLI. Click the after "AWS CLI Access:", directly under the resource to quickly copy the command.
- Utilizing scripted downloading, user batch downloads the datasets needed for local processing.
- Total cost to end user: Free

HSDS and Jupyter Notebook
Highly Scalable Data Service (HSDS) is a REST-based product and solution for reading and writing complex binary data formats within an object-based storage environment such as the Cloud. It makes large datasets accessible in a manner that is both fast and cost-effective. Jupyter Notebooks can be used at no cost to end users. Please follow the README “How to Use” section to configure HSDS and run Jupyter notebook example.
Two large datasets in OEDI have been implemented the data access with HSDS,
Wind Integration National Dataset (WIND) Toolkit
National Solar radiation Database (NSRDB)
OEDI also provides example Jupyter notebooks, which shows how to access large WIND and NSRDS datasets for free.
- User requires a sharable computational document which accesses the National Solar radiation Database.
-User is able to configure Notebook to meet the needs of the project and share with users that will benefit from the information.
- Total cost to end user: Free
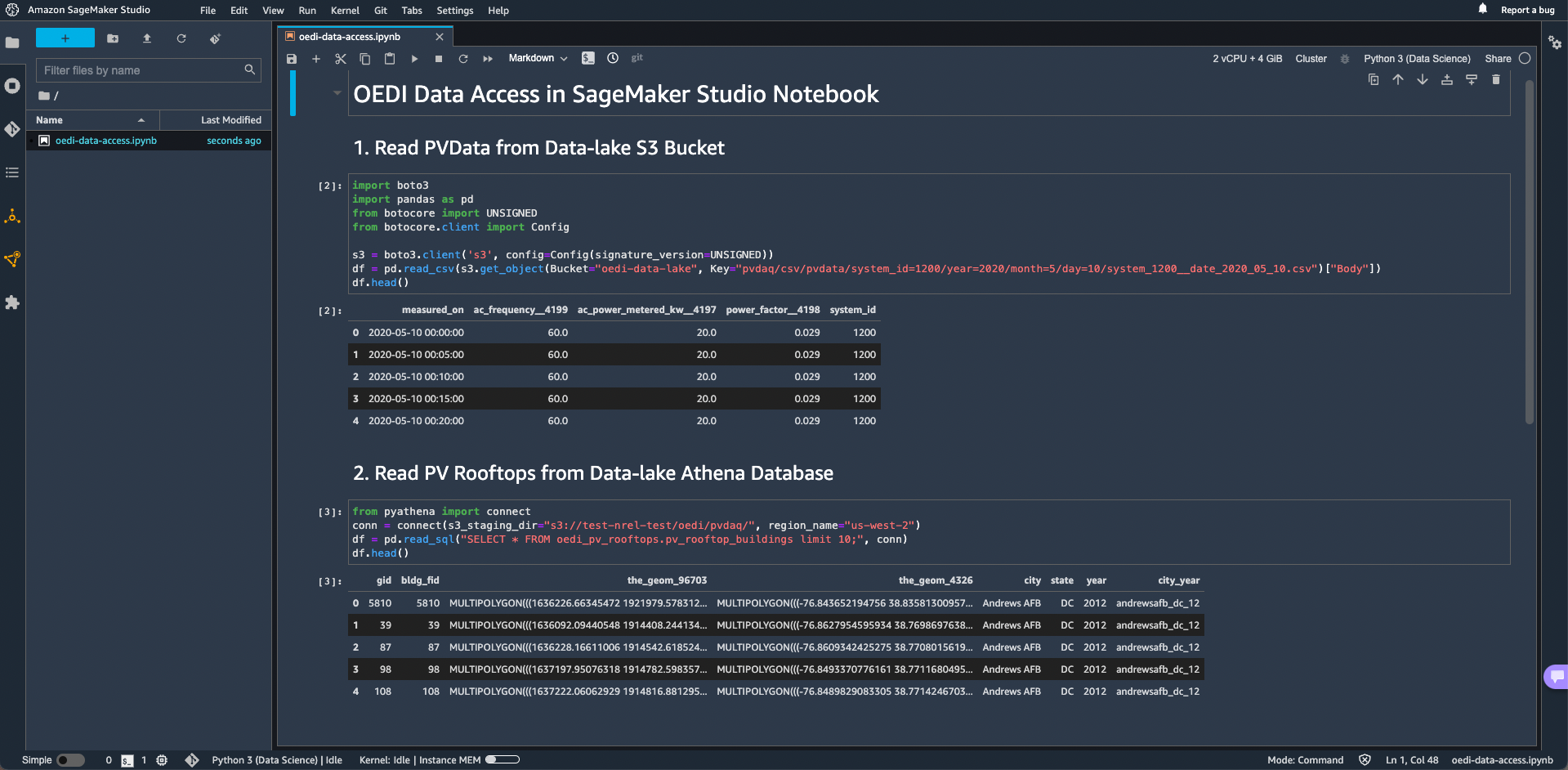
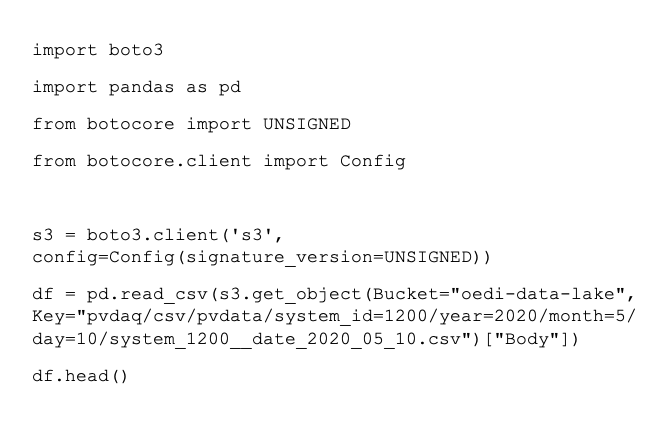
S3 Tools and APIs
Access the OEDI Data Lake using AWS S3 Tools or other APIs. Use tools like Pandas for Python to analyze OEDI datasets and make conclusions based on statistical theories.
- User wants to access data on the S3 bucket using Python.
- After installing Pandas for Python and Boto3, user can access data living in the OEDI Data Lake.
- Total cost to end user: Free
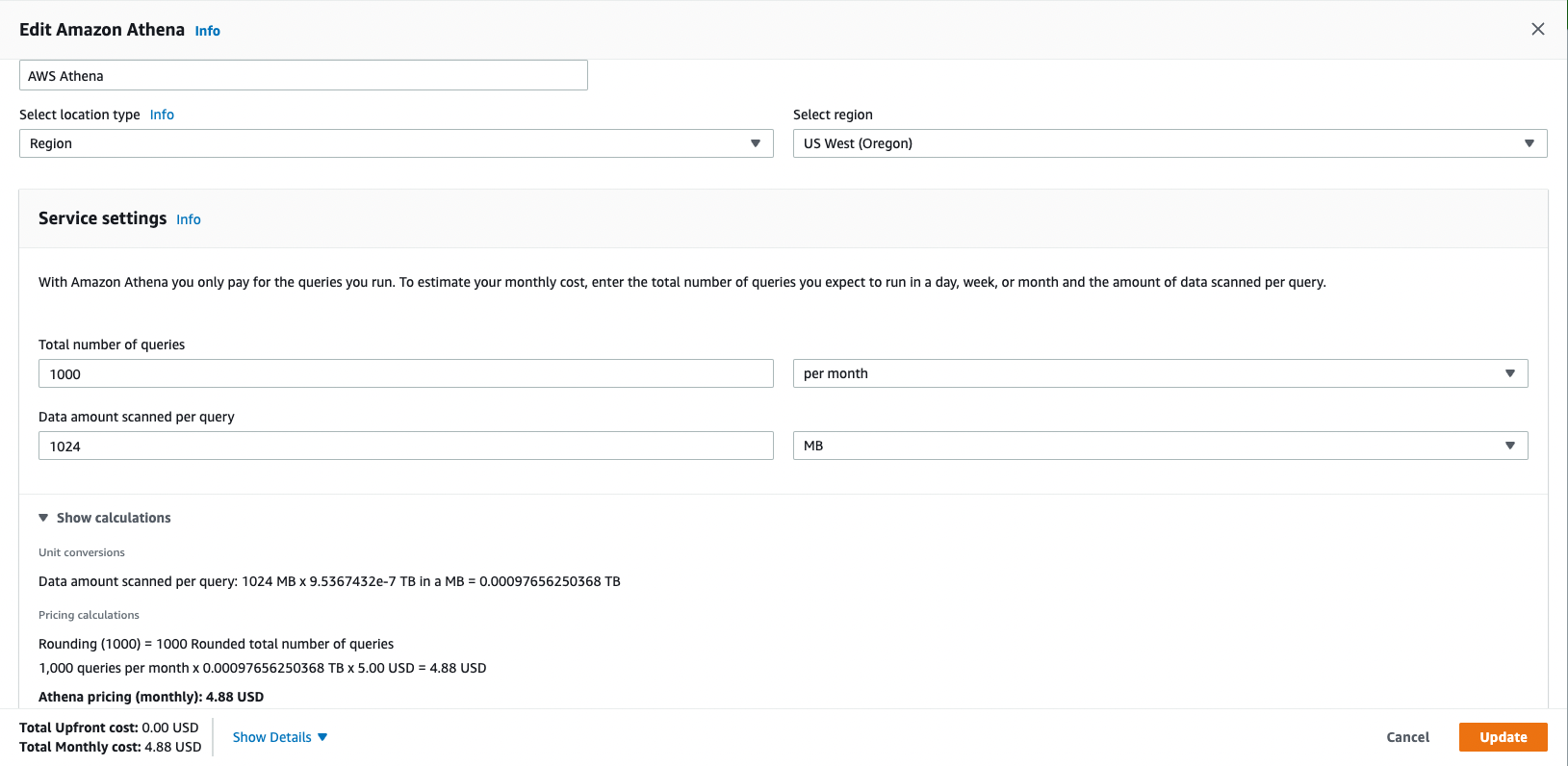
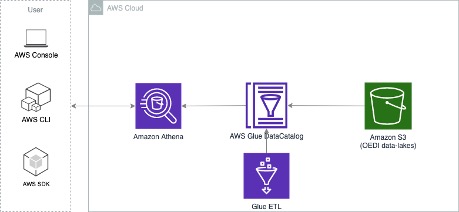
AWS Athena
Amazon Athena is an interactive query service offered by AWS that makes it easy to access data in Amazon S3 using standard SQL. Athena is serverless and users pay only for the queries that run. Under the hood, Athena uses a distributed SQL engine named Presto to run the queries, which would be powerful, standard, and fast. As Athena queries data directly in Amazon S3, it charges based on the size of the data scanned by the queries ($5 per TB of data scanned, rounded up to the nearest megabyte) with a 10MB minimum per query. Users can save 30% to 90% on per-query costs by compressing, partitioning, and converting the data into columnar formats. Additionally, this will result in better performance. AWS Athena can be used for a small fee, often less than $1.
- User requires a reoccurring 1000 monthly queries from the PV Rooftop Datasets. (318.7GB)
- The sub-dataset PV Rooftop Developable Planes is about 127.6GB. This dataset is partitioned and queried using the “city_year” field.
- This query scanned 351.5MB data in size and returned 1,585,315 records in 20 seconds with geometry information.
- The cost of this query is about $0.016 in estimate based on AWS Athena price model.
-If we run Athena queries in a regular basis, let's say 1000 queries / per month, each query would scan 1024 MB data
- Monthly cost for this example: $4.88 USD
Google BigQuery
Google BigQuery is a serverless, highly scalable data warehouse that comes with Google's built-in query engine. The engine is capable of processing SQL queries on terabytes of data in a matter of seconds, and petabytes in only minutes, as the queries are distributed and scalable. Users can access OEDI data lakes on Google Cloud Platform easily, can run big SQL queries, without having to build indexes on datasets or manage any underlying infrastructure.
BigQuery pricing has two main components Analysis and Storage pricing. Analysis pricing is the cost to process queries, including SQL queries, user-defined functions, scripts, and certain data manipulation language (DML) and data definition language (DDL) statements that scan tables. Storage pricing is the cost to store data that you load into BigQuery.
BigQuery Analysis pricing offers two models for running queries,
On-demand pricing. Users are charged for the number of bytes processed by each query ($5 per TB data scanned). The first 1 TB of query data processed per month is free. This is the default pricing option.
Flat-rate pricing. Users purchase Flex, Monthly or Annal slots (i.e. virtual CPUs) for dedicated processing capacity to run queries. This option provides predictable pricing for reoccurring queries.
- Using On-demand pricing and assuming the first free 1 TB of monthly query data has already been processed.
- For storage price, the per-month charge of active logical storage is about $0.02 per GB, and first 10GB is free each month.
- In this query, 737.77MB of data would be scanned without compression. The cost is about $0.0035 USD.
- Total cost to end user: < $0.02 USD
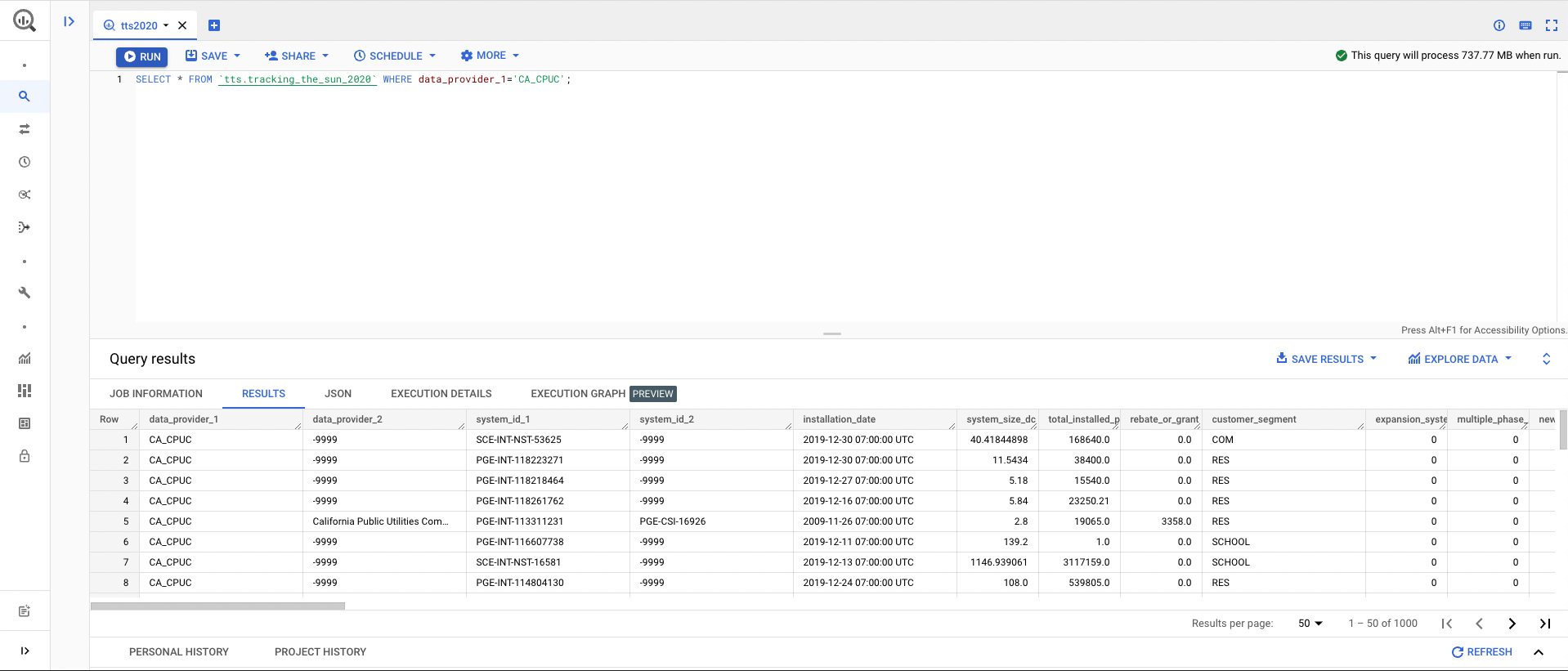
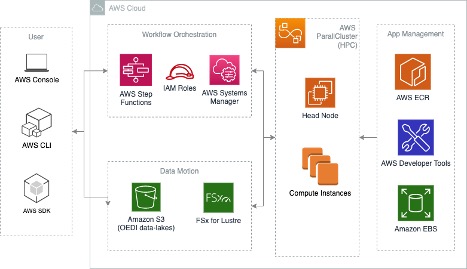
Cloud-based HPC Cluster
AWS HPC (High Performance Computing) allows users to choose any type of compute instance and storage configuration on the cloud, which could spin up in short time frames to handle the scale of variable workloads. HPC Optimized instances are purpose built to offer the best price and performance for running HPC workloads at scale. HPC instances are ideal for applications that benefit from high-performance processors such as large, complex simulations and machine learning workloads.
While managing the costs, it's a good idea with create a billing alarm to notify you via email if charges are accruing beyond a certain threshold, see Creating a Billing Alarm on AWS.
- Suppose you want to run deep learning jobs based on OEDI datasets. GPUs would be required to accelerate model training and inference processes. Here, you setup a 3 nodes cluster (1 head node, 2 compute nodes) on AWS Cloud.
- Specifications: 1 head node, t4g.small (2 CPUs, 2 GB Memory). 2 compute nodes, p3.2xlarge (8 CPUs, 61 GB Memory, 1 GPU, 16 GPU Memory). 1200 GB FSx for Lustre high-performance file system as scratch to link with OEDI S3 buckets.
- The cost of this case is approximately $6.47 per hour. If you were planning 12 hours workloads with this cluster, then the total cost for a 12 hours cluster run is about $77.62. Please note that this cost is based on On-Demand pricing model, if choosing Spot instances or Reserved instances, than the cost could be lowered to $7.76 or $21.73.
- Total cost to end user: $7.76 - $77.62 USD depending on pricing model.
- Suppose you want to run memory intensive jobs based on large OEDI datasets on a HPC cluster. You would then setup another 3 nodes cluster (1 head node, 2 compute nodes) on AWS Cloud.
-If running 12-hours compute jobs with this cluster, then the total cost would be $2.16 with On-Demand. This would be much cheaper if with Spot instances or Reserved instances.
- Total cost to end user: $2.16 USD with On-Demand pricing
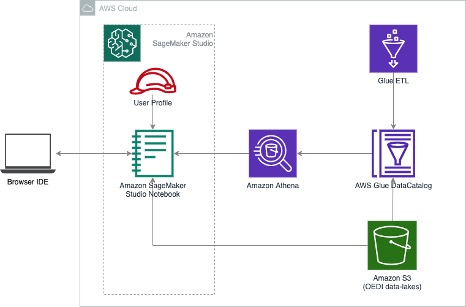
AWS SageMaker Studio
The SageMaker Studio is the core of many Machine Learning (ML) and MLops workflows built on AWS Cloud. It's a fully managed machine learning service. Scientists or engineers can use SageMaker to quickly build and train ML models and then deploy them into production-ready environment. It provides a web-based integrated development environment (IDE), where users can see and interact with all ML workflows in SageMaker on AWS. SageMaker Studio provides a workspace with hosted Jupyter notebooks and elastic compute resources, letting users to manage end-to-end machine learning processes. This includes model training, running, debugging, deployment, and monitoring. See documentation for setup and configuration.
Amazon SageMaker Savings Plan helps to reduce the costs by up to 64% compared to On-Demand pricing. With SageMaker Studio Notebook, it's very easy to upgrade/downgrade the instance types to affect charge rates. See pricing for additional rate information.
- In this demo, this notebook is spinning up on a ml.t3.medium instance (2 CPUs, 4 GB Memory), the On-Demand cost of this instance is $0.05 per hour ($1.20 USD per day).
-If we work with ML tasks on top of OEDI datasets using this notebook for a month (30 days), then the cost would be $36.00 USD.
-Amazon SageMaker Savings Plan could help to reduce the costs by up to 64% compared to On-Demand pricing above. The monthly running cost of ml.t3.medium instance would be lowered to $12.96 USD.
- Total cost to end user: $36.00 - $12.96 USD depending on pricing model.
AWS SageMaker Studio Lab
Amazon SageMaker Studio Lab is a free machine learning (ML) development environment that provides the compute, storage (up to 15GB) and security to learn and experiment with ML. The account owner pays only for the compute consumed by the nodes. No cost to end users. SageMaker Stuio Lab is a simplified, abbreviated variant of SageMaker Studio. It's based on the same architecture and user interface as SageMaker Studio. Though, limited by compute, storage and a subset of SageMaker capacilities.
Key features:
-Free, no credit card or AWS account needed.
-Based on the open-source and extensible JupyterLab IDE within browser, no installation required.
-Flexible CPU or GPU session choices to better suite project model training.
-15GB of free long-term persistent storage for what you build.
-Pre-packaged ML frameworks with no configuration required to run Jupyter notebooks.
Please aware of compute & storage resources limitation when experimenting with OEDI datasets,
-15 GB of persistent storage
-16 GB of RAM
-One CPU or GPU compute each time with project runtime
-CPU runtime is limited to 12 hours per session.
-GPU runtime is limited to 4 hours per session, no more than a total of 8 hours in a 24-hour period.
-Availability of CPU or GPU runtimes is not guaranteed and is subject to demand.
- User requires access to data in the data lake from 6 Jupyter notebooks, hosted in Amazon’s Sagemaker Studio Lab. The individual notebooks are connected to the data and can run machine learning algorithms against the data.
- User can interact with terabytes of data and run advanced algorithms from any laptop or mobile device with an internet connect. No installation is required by the user end.
- Actual cost hosting 6 nodes for a 3-day workshop (three 8-hour days): $52. (incurred by workshop organizer on their AWS account)
- Total cost to end user: Free